离线运行的本地语音识别服务
一个基于 fast-whisper 模型的本地离线语音识别工具,支持将视频/音频中的人类声音转换为文字,输出格式包括 json、srt 字幕和纯文本。提供 API 接口,支持多语言和多种模型,适用于替代商业语音识别服务。
• Copy the embed code to showcase this product on your website
• Share on X to spread the word about this amazing tool
https://github.com/jianchang512/stt这是一个离线运行的本地语音识别转文字工具,基于 fast-whipser 模型,将 视频/音频 中的人类声音识别并转为文字,可选文字输出格式:json、srt字幕、纯文字。可用于自行部署后替代 openai 的语音识别接口或百度语音识别等,准确率基本等同openai官方api接口。## 特点1. 本地离线工作2. 提供 api 调用接口3. 使用 openai-whisper 开源模型4. win下提供预编译exe版本,双击即可使用,无需部署5. 支持 win/mac/linux 源码部署## 预览视频https://github.com/jianchang512/stt/assets/3378335/d716acb6-c20c-4174-9620-f574a7ff095d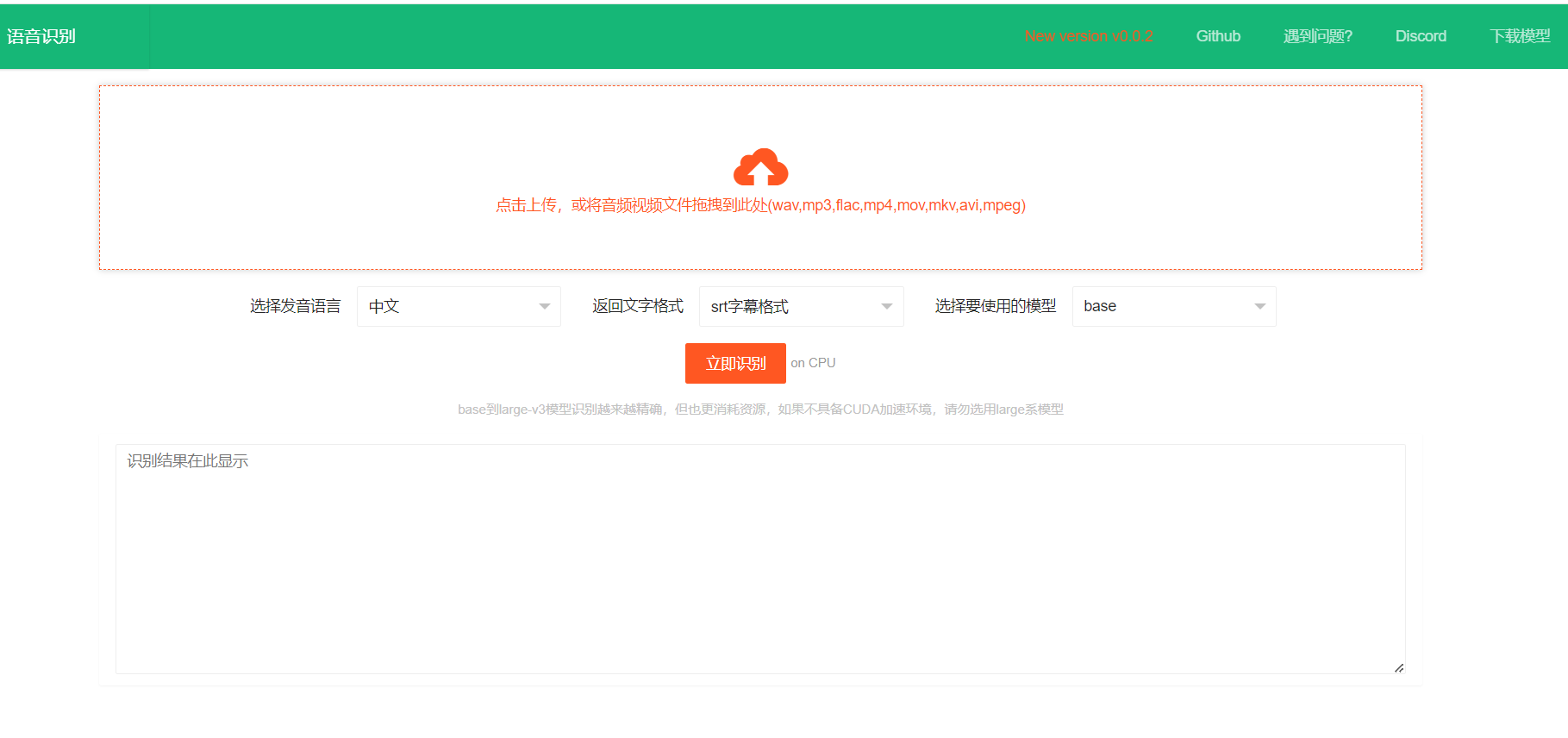## api 接口接口地址: http://127.0.0.1:9977/api请求方法: POST请求参数: language: 语言代码:可选如下 > > 中文:zh > 英语:en > 法语:fr > 德语:de > 日语:ja > 韩语:ko > 俄语:ru > 西班牙语:es > 泰国语:th > 意大利语:it > 葡萄牙语:pt > 越南语:vi > 阿拉伯语:ar > 土耳其语:tr > model: 模型名称,可选如下 > > base 对应于 models/base.pt > small 对应于 models/small.pt > medium 对应于 models/medium.pt > large 对应于 models/large.pt > large-v3 对应于 models/large-v3.pt > response_format: 返回的字幕格式,可选 text|json|srt file: 音视频文件,二进制上传Api 请求示例python import requests # 请求地址 url = "http://127.0.0.1:9977/api" # 请求参数 file:音视频文件,language:语言代码,model:模型,response_format:text|json|srt # 返回 code==0 成功,其他失败,msg==成功为ok,其他失败原因,data=识别后返回文字 files = {"file": open("C:\\Users\\c1\\Videos\\2.wav", "rb")} data={"language":"zh","model":"base","response_format":"json"} response = requests.request("POST", url, timeout=600, data=data,files=files) print(response.json())